От переводчика. Это начало перевода цикла статьей XQuery for the Non-Expert. В данном переводе отсутствует статья "XQuery for the Non-Expert – Terminology", описывающая что такое элементы, атрибуты XML, XML-документ и т.д. Мне кажется данные понятия должны быть понятными для многих IT специалистов.
Пространства имен XML
Давайте поговорим о пространствах имен XML. Вы взволнованы? Ощущаете ли вы мурашки по коже от волнения или скорее от беспокойства при мысли использования данного оператора T-SQL?
Целью статьи является сделать XQuery и его функции и операторы более легкими для усвоения. Надеюсь, что после нескольких примеров и некоторых аналогий, вы будете понимать их на профессиональном уровне.
Что такое пространства имен XML?
Хорошо, давайте начнем с определения. Ниже приводится определение из Википедии
Пространства имён в XML - это стандарт, описывающий именованную совокупность имён элементов и атрибутов, служащую для обеспечения их уникальности в XML-документе. Они определены в рекомендации W3C. XML-документ может содержать имена элементов или атрибутов из нескольких словарей XML. Неоднозначность между одинаковыми именами элементов или атрибутов может быть решена, если каждый словарь задает свое пространство имен.
Что же, хорошо. Мы тут не эксперты. Давайте использовать немного более простое определение.
Пространство имён в XML - это схема XML-документа. Оно определяет все возможные атрибуты и значения для каждого узла. Оно определяет каждый из узлов. Оно также обеспечивает логическую структуру XML-документа.
Картинка, картинка
Да, да. Ох уж эти определения. Давайте взглянем на него с другой стороны. Предположим, что у вас имелась схема базы данных, похожая на модель ниже. На ней имеются таблицы Customer, Address, Order и Item.
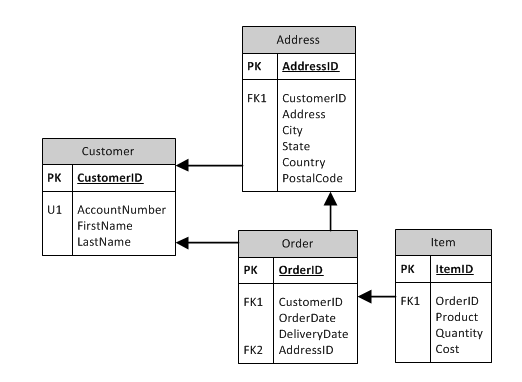
Рисунок 1
На основе этой модели мы знаем несколько вещей. Очевидно, что есть четыре таблицы. Но мы также знаем, что есть связи между таблицами Customer и Address, Customer и Order, Order и Address, Order и Item.
XML-представление
Как вы можете предполагать, информация в этих таблицах также может быть представлена в XML-формате. Для какого-нибудь клиента XML-документ может выглядеть так:
<Customer AccountNumber="1234" FirstName="Jason" LastName="Strate">
<Order OrderDate="2010-11-06">
<Address Address="456 First Street" City="Minneapolis" State="MN" PostalCode="55441" />
<Item ProductID="12" Quantity="34" Cost="45" />
<Item ProductID="34" Quantity="45" Cost="56" />
<Item ProductID="56" Quantity="7" Cost="89" />
</Order>
<Address Address="123 Main Street" City="Minneapolis" State="MN" PostalCode="55441" />
</Customer>
Проблема с XML, представленной выше, в том, что мы ничего не знаем о ее структуре, кроме данных, которые в ней находятся. Есть ли ограничения на допустимые значения атрибута State? Могут ли входить в элемент Order несколько элементов Address? Эти и другие вопросы остаются без ответов.
Здесь нужно что-то, что определяло бы, что это за структура. Как указано выше, пространство имён XML предоставляет эту информацию. Это виртуальная схема к XML-структуре, которая гарантирует, что каждый узел, атрибут, сущность и т.д. будет вести себя определенным образом для всех XML-документов, к которым она может быть применена.
А теперь применим
Хотелось бы надеяться, что к этому моменту вы понимаете цель пространств имен XML. Проблема в том, что довольно бесполезно, если мы не знаем, как их применить к XML-документу.
Есть несколько способов, с помощью которых пространства имен XML могут быть использованы с XQuery выражениями:
- указать его в запросе и установить его в качестве пространства имен по умолчанию для запроса;
- указать его в запросе и предоставить псеводним для пространства имен в запросе;
- указать его в XQuery-функции и установить его в качестве пространства имен по умолчанию для функции;
- указать его в XQuery-функции и предоставить псеводним для пространства имен в функции.
Это все способы его применения, о которых я знаю. Для простоты я буду все время пытаться делать акцент на первом варианте, при написании XQuery-запросов в этом блоге.
Этот метод использовать просто с помощью инструкции WITH в начале вашего XQuery выражения. Используйте предложение XMLNAMESPACES с ключевым словом DEFAULT рядом с URL-адресом пространства имен.
WITH XMLNAMESPACES(DEFAULT N'http://url/of/xml/namespace') SELECT Column1, Column2, … FROM dbo.SomeTable
Как будет все сделано, все XML-документы, к которым будут обращения, используют указанное пространство имен.
Метод nodes()
Там, где выражение XMLNAMESPACES является картой по XML-документу, метод nodes() является навигатором, который поможет вам перемещаться по XML-документу.
Так как данные в XML-документе являются не совсем читабельными, метод nodes() поможет вам разделить ваши XML-документы на части. Таким образом, вложенные элементы XML-документа могут быть извлечены и возвращены в виде строк.
Возможности nodes()
Давайте быстро покажем, что может быть сделано с помощью метода nodes(). Допустим, что у вас есть следующий XML:
<Building type="skyscraper">Sears Tower
<Floor level="1" />
<Floor level="2" />
<Floor level="3">
<Floor level="3.1" />
</Floor>
</Building>
Этот XML может быть разделен на части двумя способами в зависимости от элемента Floor. Во-первых, мы можем искать все элементы Floor, которые находятся внутри элемента Building. Результат будет таким:
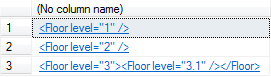
Рисунок 2
Альтернативно XML может быть разделен на части, чтобы вернуть все элементы Floor XML-документа. Результат будет таким:
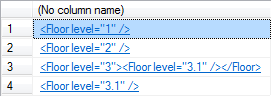
Рисунок 3
Синтаксис nodes()
Теперь, когда мы видели, как метод nodes() может повлиять на XML-документ, мы должны посмотреть, как его использовать. Во-первых, вот синтаксис метода nodes():
nodes (XQuery) as Table_Alias(Column_Alias)
Так как синтаксис не объясняет то, как его использовать, мы сейчас его немного разберем:
- nodes - название метода. Он всегда должен быть в нижнем регистре. Это одно из первых вещей, которые я проверяю, когда люди имеют проблемы с запросом, потому что это общая проблема.
- XQuery - XQuery выражение, которое указывает методу nodes(), каким образом разделять XML-документ. Есть несколько способов работы с ним, которые будут рассмотрены в дальнейших иллюстрациях. Ключевой момент, который необходимо запомнить - это то, что XQuery выражение очень похож на UNC-путь. Если вы будете рассматривать элементы XML-документа так, как будто они являются папками файловой системы, то XQuery выражение будет путем для просмотра документа.
- Table_Alias - имя таблицы для результирующего набора строк, полученного разбором на части XML-документа. Его можно не использовать, пока имя столбца этой таблицы не совпадает с именем столбца другой таблицы вашего запроса.
- Column_Alias - имя столбца для результирующего набора строк, полученного разбором на части XML-документа. Получить доступ к разным частям разобранного XML можно с помощью этого столбца.
Метод nodes() вызывается как метод столбца, который возвращает XML данные. При работе с ним он часто будет вызываться с помощью оператора APPLY, чтобы могли быть запрошены сразу несколько документов XML.
Подготовка к nodes()
Используя вышеприведенный синтаксис, давайте выполним пару примеров, чтобы показать то, как получить результирующий набор строк из рисунка 2. Для начала, мы создадим таблицу и добавим в нее наш пример XML-документа.
IF OBJECT_ID('tempdb..#NodesExample') IS NOT NULL
DROP TABLE #NodesExample
GO
CREATE TABLE #NodesExample
(
XMLDocument xml
)
INSERT INTO #NodesExample
VALUES ('<Building type="skyscraper">Sears Tower
<Floor level="1" />
<Floor level="2" />
<Floor level="3">
<Floor level="3.1" />
</Floor>
</Building>')
SELECT XMLDocument FROM #NodesExample
Прежде чем мы начнем извлекать элементы XML-документа, давайте представим его в виде дерева каталогов. Если бы пример XML-документа был бы структурой папок, он бы выглядел примерно так:

Рисунок 4
Чтобы обратиться к папке Floor через эту структуру папок, UNC-путь может выглядеть так: "\\XMLDocument\Building\Floor". XMLDocument будет выброшен, т.к. это имя столбца, и UNC-путь изменится на "\Building\Floor".
Давайте для простоты зададим для Table_Alias и Column_Alias соответственно значения t и c. Они могут принимать любые значения, которые имеют смысл для запроса. Мы их оставим простыми, так как это будут просто примеры.
Примеры использования nodes()
Чуть ранее были показаны два примера результирующих наборов строк. Оба они могут быть получены из XML-документа, представленного выше в примере скрипта. Мы продемонстрируем как это сделать на следующих примерах пары скриптов.
Для первого результирующего набора строк нам нужно поделить XML, чтобы вернуть каждый элемент Floor каждого элемента Building. В выражении XQuery используйте UNC-путь, представленный выше, с прямым слешем вместо обратного. Мы будем начинать выражение XQuery с одиночным прямым слешем; это будет говорить методу nodes() начать с начала XML документа или фрагмента. Тогда псевдонимы и XQuery выражение должны быть следующими:
SELECT c.query('.')
FROM #NodesExample
CROSS APPLY XMLDocument.nodes('/Building/Floor') as t(c)
Пока просто игнорируйте метод query(), он будет описан позже. Выполнение этого запроса вернет результат, показанный на рисунке 2. Я не хочу снова вставлять картинку результата запроса, вы можете его выполнить и сравнить ваш результат.
Для второго результирующего набора строк нам нужно найти все элементы Floor в XML. Используя принцип, похожий на UNC соглашение, метод nodes() может быть использован для поиска в XML-документе всех "папок" (или элементов) с именем Floor.
Для этого добавьте в начале имени элемента Floor двойной прямой слеш. Это сообщит методу nodes() вернуть все элементы с этим именем. Запрос в этом случае будет выглядеть следующим образом:
SELECT c.query('.')
FROM #NodesExample
CROSS APPLY XMLDocument.nodes('//Floor') as t(c)
Этот запрос вернет результат, похожий на результирующий набор строк из рисунка 3. Давайте, выполните его и вы можете проверить результат.
Есть одна последняя вещь, касающееся метода nodes(), которую нужно упомянуть. Переход по папкам с помощью XQuery не ограничивается одним, двумя или тремя уровнями иерархии. Используйте его, чтобы рыться в вашем XML так глубоко, как вам необходимо.
Эта статья не описывает операторы CROSS APPLY и OUTER APPLY. Вы должны быть знакомы с ними, чтобы писать выражения XQuery. Если у вас не было опыта их использования, потратьте немного времени, чтобы их изучить.
Метод query()
Основным применением метода query() является получение дочерних элементов с помощью просмотра более низких уровней XML-документа.
Иногда, когда метод nodes() используется для просмотра XML-документа, вам необходимо получить кусок XML, который был запрошен. Метод query() может использоваться для возврата фрагмента XML.
Синтаксис query()
Общий синтаксис метода query() следующий:
query ('XQuery')
XQuery - это выражение, который указывает методу query(), каким образом просматривать XML документ или фрагмент. Более подробное объяснение выражений XQuery было приведено ранее.
Метод query() вызывается как метод столбца, который содержит XML данные. Этот метод может быть вызван в инструкции SELECT.
Подготовка к query()
Чтобы показать способы применения метода query(), давайте создадим таблицу, содержащую XML-документ. Выполните следующий запрос для подготовки к следующим примерам:
IF OBJECT_ID('tempdb..#QueryExample') IS NOT NULL
DROP TABLE #QueryExample
GO
CREATE TABLE #QueryExample
(
XMLDocument xml
)
INSERT INTO #QueryExample
VALUES ('<Building type="skyscraper">Sears Tower
<Floor level="1" />
<Floor level="2" />
<Floor level="3">
<Room number="3.1" />
<Room number="3.2" />
</Floor>
<Floor level="4">
<Room number="4.1" />
<Room number="4.2" />
</Floor>
</Building>')
SELECT XMLDocument FROM #QueryExample
Теперь, когда у нас есть что-то, с чем можно поиграть, давайте пойдем дальше и применим метод query().
Примеры использования query()
В первом примере метод query() будет использован для получения всех элементов, которые содержатся в одном из родительских элементов. В запросе мы вернем элементы Room, которые находятся под элементами Building и Floor ("/Building/Floor/Room").
Запрос будет похожим на следующий:
SELECT XMLDocument.query('/Building/Floor/Room')
FROM #QueryExample
Выше метод query() используется в инструкции SELECT и просматривает два уровня от корневого элемента Building до элемента Room. Результат запроса будет следующим:

Рисунок 5
Далее результат в виде XML:
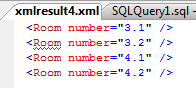
Рисунок 6
Эти результаты сильно отличаются от результатов метода nodes(). С помощью nodes() каждый XML-фрагмент возвращался в отдельной строке. Тогда как при использовании метода query() все элементы, соответствующие выражению XQuery, вернулись в единственном XML-фрагменте.
Другой способ использования метода query() заключается в замене XQuery выражения в параметре метода на точку или две точки. Когда используется одинарная точка, query() возвращает фрагмент XML, который вернул метод nodes(). Если используются две точки, то возвращается XML фрагмент с родительскими элементами.
Чтобы продемонстрировать это, измените запрос следующим образом:
SELECT c.query('.') OnePeriod, c.query('..') TwoPeriods
FROM #QueryExample
CROSS APPLY XMLDocument.nodes('/Building/Floor/Room') as t(c)
Результат запроса будет выглядеть следующим образом:

Рисунок 7
Вывод в XML-формате при передаче одной точки в query() будет следующим:
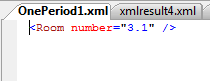
Рисунок 8
Вывод в XML-формате при передаче двух точек в query() будет следующим:

Рисунок 9
Как видно по результатам, метод query() возвращает фрагменты XML, которые были разделены методом nodes(). Это очень полезно при разделении и попытке отобразить XML в результатах запроса, когда требуется определить, правильные ли данные возвращает метод nodes().
Продолжение следует...
Комментариев нет:
Отправить комментарий